# Spiders
Los scripts que se encargan de hacer WebScrapping Scrapy los llama Spiders
cada uno hereda de la clase Spider y contiene un metodo principal llamado parse.
my-spider.py
# -*- coding: utf-8 -*-
from scrapy import Spider, CrawlSpider, BaseSpider # hay diefreentes tipos de Spiders
class MySpider(Spider):
name = "my-spider"
start_urls = (,) # urls iniciales debe ser una lista o una tupla
def parse(self, response):
# ...
# Generando Spiders
Podemos generar nuestros spiders desde la terminal o crear los archivos de python directamente solo hay que respetar la estructura básica necesaria para que Scrapy pueda indentificarlos
$ scrapy genspider <NOMBRE_SPIDER> <DOMINIO> # creación simple
# Etiqueta HTML
# CSS & XPath Selector
A continuación se muestran 2 ejemplos que extraen los mismos datos del sitio web, pero toscrape-css
emplea selectores CSS, mientras que toscrape-xpath emplea expresiones XPath.
# Ejemplo de scraping usando selectores CSS
import scrapy
class ToScrapeCSSSpider(scrapy.Spider):
name = "toscrape-css"
start_urls = [
'http://quotes.toscrape.com/',
]
def parse(self, response):
"""
"""
# hay que tomar encuenta que es una busqueda asi que
# devuelve siempre una lista o arreglo
# div.quote => '<div class="quote">...</div>'
for quote in response.css("div.quote"):
yield {
# span.text => '<span class="text">...</span>' y ::text le indica
# que no debe retornar la etiqueta sino el texto dentro de ella
'text': quote.css("span.text::text").extract_first(), # extract_first() obtiene el primer elemento
'author': quote.css("small.author::text").extract_first(),
# > el signo menor o igual indica que debe extraer los hijos
# div.tags > a.tag => '<div class="tags"> <a class=""tag>Poema</a>... </div>'
'tags': quote.css("div.tags > a.tag::text").extract() # extract() obtiene todos los elementos encontrados
}
# devuelve la URL dentro de la etiqueta a
next_page_url = response.css("li.next > a::attr(href)").extract_first()
if next_page_url is not None:
yield scrapy.Request(response.urljoin(next_page_url)) # procesar la siguiente URL
# Ejemplo de scraping utilizando XPath
# -*- coding: utf-8 -*-
import scrapy
class ToScrapeSpiderXPath(scrapy.Spider):
name = 'toscrape-xpath'
start_urls = [
'http://quotes.toscrape.com/',
]
def parse(self, response):
for quote in response.xpath('//div[@class="quote"]'):
yield {
'text': quote.xpath('./span[@class="text"]/text()').extract_first(),
'author': quote.xpath('.//small[@class="author"]/text()').extract_first(),
'tags': quote.xpath('.//div[@class="tags"]/a[@class="tag"]/text()').extract()
}
next_page_url = response.xpath('//li[@class="next"]/a/@href').extract_first()
if next_page_url is not None:
yield scrapy.Request(response.urljoin(next_page_url))
# Response Object
Uno de los objetos más importantes del spider es response ya que en el se encuentra todo
la información del sitio, url, página que estamos visitando es como si tuvieramos en navegador
almacenado en un objeto.
Hay algunas propiedades importantes que son útiles en las diferentes situaciones que podemos toparnos cuando extraemos información de un sitio.
response.headers # acceder a los headers de la respuesta
response.text # texto plano de la respuesta
response.body # html o formato de la respuesta
response.css # selector css
response.xpath # selector xpath
# Login with FormRequest
Para procesar formularios en general podemos utilizar la clase FormRequest y llamar al método from_response para procesar un formulario dentro de la misma pagina visitada. Es útil para inicio de sesiones pasandole los datos necesarios para rellenar el formulario.
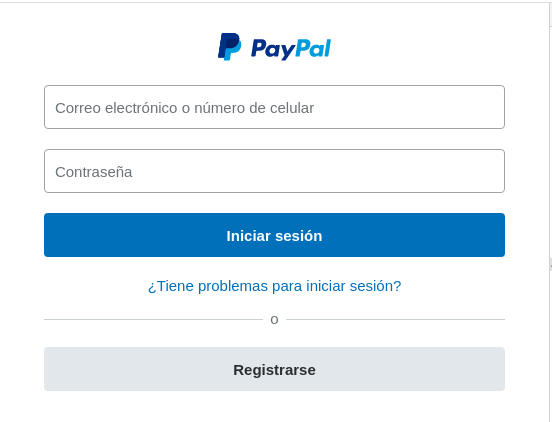
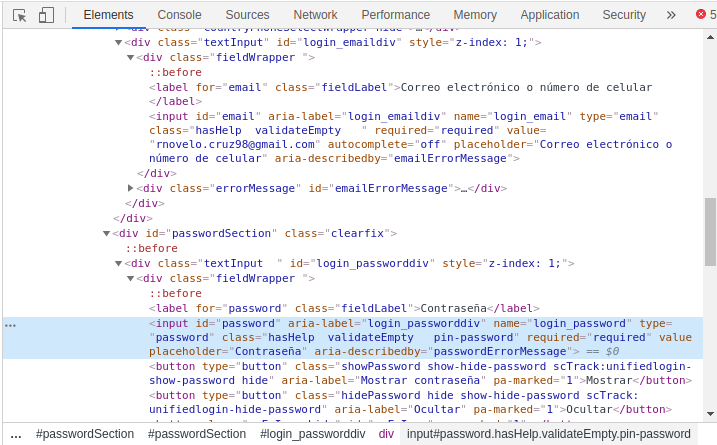
Para este ejemplo utilizaremos el formualrio de inicio de sesion de PayPal para ello
saber el valor del atributo name en los <input> que queremos rellenar. Asi como el id y type del botón.
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
from scrapy.http import FormRequest
from scrapy.utils.response import open_in_browser # for testing
class PaypalSpider(scrapy.Spider):
name = 'paypal' # spider name
start_urls = ['https://www.paypal.com/signin/'] # main url
def parse(self, response):
# En algunos casos necesitaremos extraer datos de elementos ocultos pero que son enviados en la request
# en este caso necestamos extraer un token
token = response.xpath('//*[@name="_csrf"]/@value').extract_first()
# los valores deben coincidir con el formualrio
data = {'_csrf': token, 'login_email': 'EMAIL', 'login_password': 'PASSWORD' }
yield FormRequest.from_response(response, formdata=data,
callback=self.after_login)
def after_login(self, response):
"""Crawl site with user session"""
div = response.css('div').extract_first()
print(div)
# Network & request
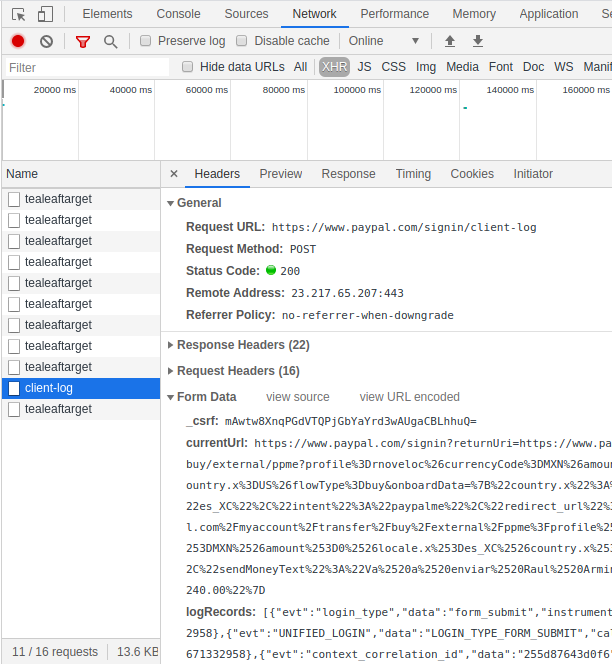
En este punto hay que prestar mucha atención de como la pagina en cuestión envia los datos al servidor en algunos casos podemos encontrarnos con problemas para el bot. Alguno de los más comunes:
- Uso de cookies para manejar sesiones
- Single Page Applications
En otros casos es importante fijarnos en la sección de Network del navegador para saber si es necesario hacer scraping o podemos consumir los servios REST o HTTP.
# Running the spiders
Puede ejecutar un spider utilizando el comando scrapy crawl:
`$ scrapy crawl toscrape-css`
Si nuestro spider esta configurado para devolver arrays estos pueden guardarse en un archivo, puede usar la opción -o:
`$ scrapy crawl toscrape-css -o quotes.json`
Los formatos disponibles son:
- XML
- CSV
- JSON
Si queremos correr un spider directamente desde el archivo podemos usar scrapy runspider
apuntando a su direccion en el directorio:
`$ scrapy runspider /to/path/SPIDER_NAME.py`